

Data Orchestration for Modern Business
Automate your data management to create and maintain engagement-ready data with ZoomInfo Operations.


7,000+ G2 Reviews

Ranked #1 in 30+ Categories
By submitting this form, you are agreeing to ZoomInfo’s Privacy Policy and Terms of Service.











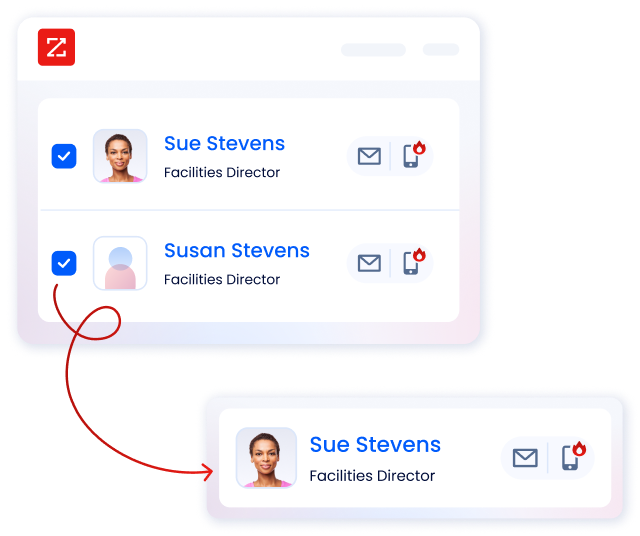
DATA DEDUPLICATION
Match and dedupe to increase data quality
Begin your data cleansing process with custom, hands-off record matching and deduplication.
Automate deduplication with customized rules
Seamlessly merge and archive deduplicated data
Match leads to their correct accounts
Prevent bad data from entering your systems of record in real time

DATA CLEANSING
Cleanse data of errors and inconsistencies
Transform records into a consistent, actionable format with a drag-and-drop interface.
Automate data corrections with pre-configured formatting
Normalize and standardize phone numbers, company names, ISO codes, proper case, and more
Transform data in bulk or in real time

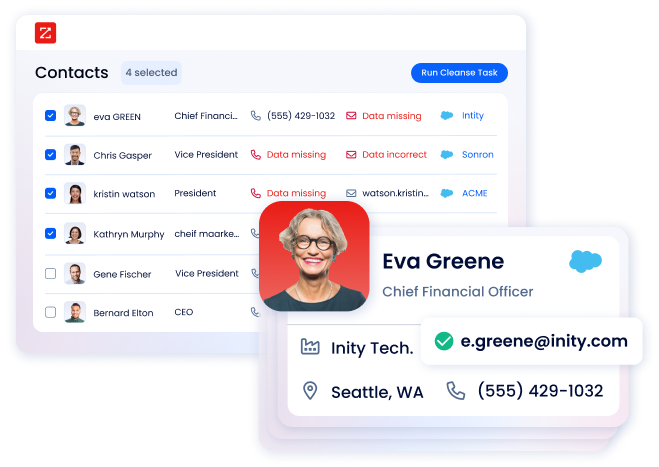
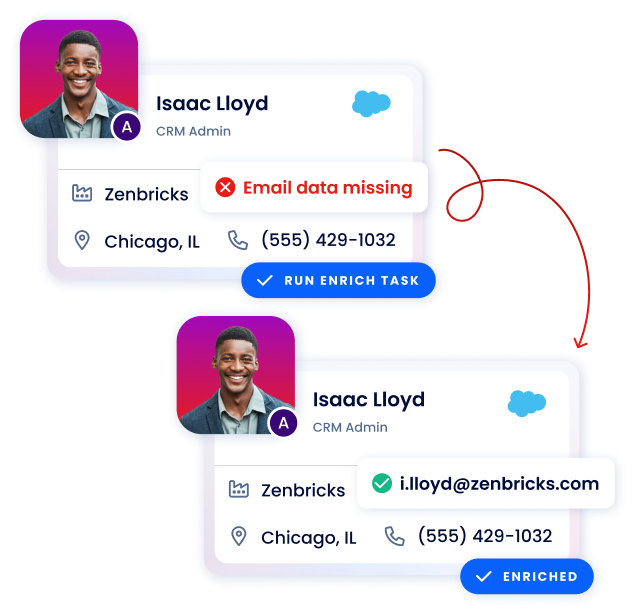
Data Enrichment
Increase data completeness by enriching in bulk and in real time
Append your CRM, marketing automation platforms and other business technologies at the frequency of your choice with easy-to-configure enrichment workflows.
Leverage multi-vendor enrichment by connecting to any API-based data source
Customize what data gets enriched from which source with waterfall logic
Increase data completeness by enriching in bulk and in real time

CORE FEATURES
Drive better processes with engagement-ready data

Data Management
Power business operations using best-in-class data — ranked #1 in G2’s categories for Sales Intelligence and Account Data Management.
Learn more about Data EnrichmentWorkflows
Ranked #1 in Buyer Intent on G2, ZoomInfo Operations helps teams act fast on market signals, from buyer intent to tech installations, with automated outreach and sales activities.
Learn more about WorkflowsData Services
Our dedicated data services managers support your business’s custom data delivery and modeling needs.
Learn more about Data ServicesGTM Teams
How ZoomInfo Powers RevOps
For Leaders
With data-driven solutions integrated across channels and technologies, leaders can drive scalable results.Read Case StudyFor Marketing
With reliable data-driven solutions, marketers can say goodbye to sunk costs and hello to strategic partnerships with sales. “ZoomInfo enables our sales and marketing teams to be aligned on the best prospects to target resulting in time saved and more deals closed.”Read Case StudyFor Sales
“ZoomInfo’s Operations Data Management Suite arms us with the technology and data to match, unify, dedupe, normalize, cleanse, enrich, score and route data through a single source of truth.”Read Case Study


“Our experience with ZoomInfo has been exceptional.
The data, automation and customer service is unmatched.”
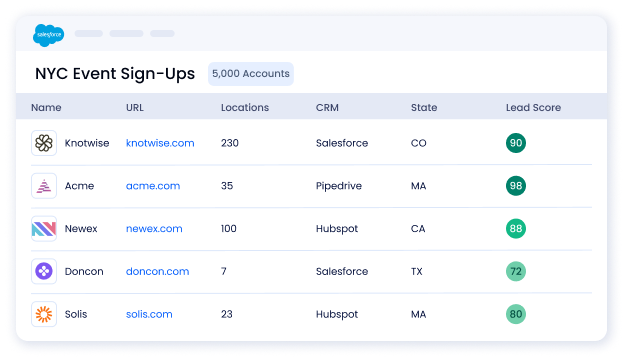
USE CASES
Finally, data-driven solutions modern go-to-market teams can depend on
Unify teams and technologies across your go-to-market channels.


Lead Scoring
Learn MoreSegment and score to prioritize leads based on job function, seniority, industry, and company size, and over 300+ custom attributes. Score any object based on any attribute.
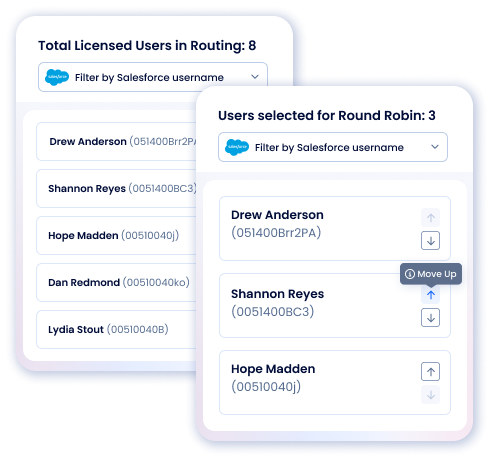
Lead Routing
Learn MoreManage SLAs confidence and hand engagement-ready leads to the right rep at the right time to shorten your sales cycle. ZoomInfo Route offers an easy-to-use customizable, rules-based engine along with optimized, round-robin distribution using weighting and capping.
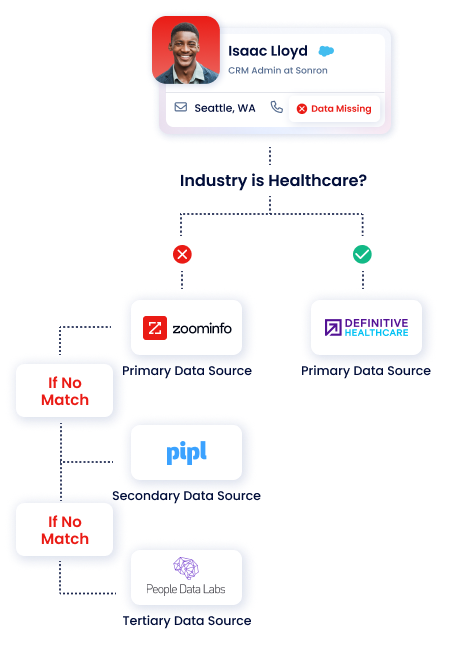
Multi-vendor Enrichment
Learn MoreLeverage multi-vendor enrichment by connecting to any API-based data source, customizable by source with waterfall logic.



INTEGRATIONS
Meet Our Partners
Accelerate your go-to-market motions by transitioning from complex B2B data ingestion to cutting-edge data management. ZoomInfo partnerships with leading cloud solutions maximize your data’s value and accessibility with flexible access and delivery.
Case Studies
Here are just a few ways 35,000+ customers use ZoomInfo’s best-in-class data to power their Go-to-Market.

Reduced speed to lead from 20 minutes to 60 seconds
“Thanks to ZoomInfo, we no longer have to question the source or reliability of the data in our systems. We’re now able to enrich and integrate data in any workflow, in real-time, at scale.”

Improved savings with consolidated tech stack
“We’re no longer working in silos. Our tech stack is a fully integrated system that encourages productivity and is underpinned by a single source of truth which offers deep insights into our total addressable market.”

Increased marketing-sourced pipeline by grew 60%
“ZoomInfo has played a huge role in our growth rate. We rely on the tools in our tech stack to get the job done, and already we are at a 33% growth rate in the first quarter [of 2023].”